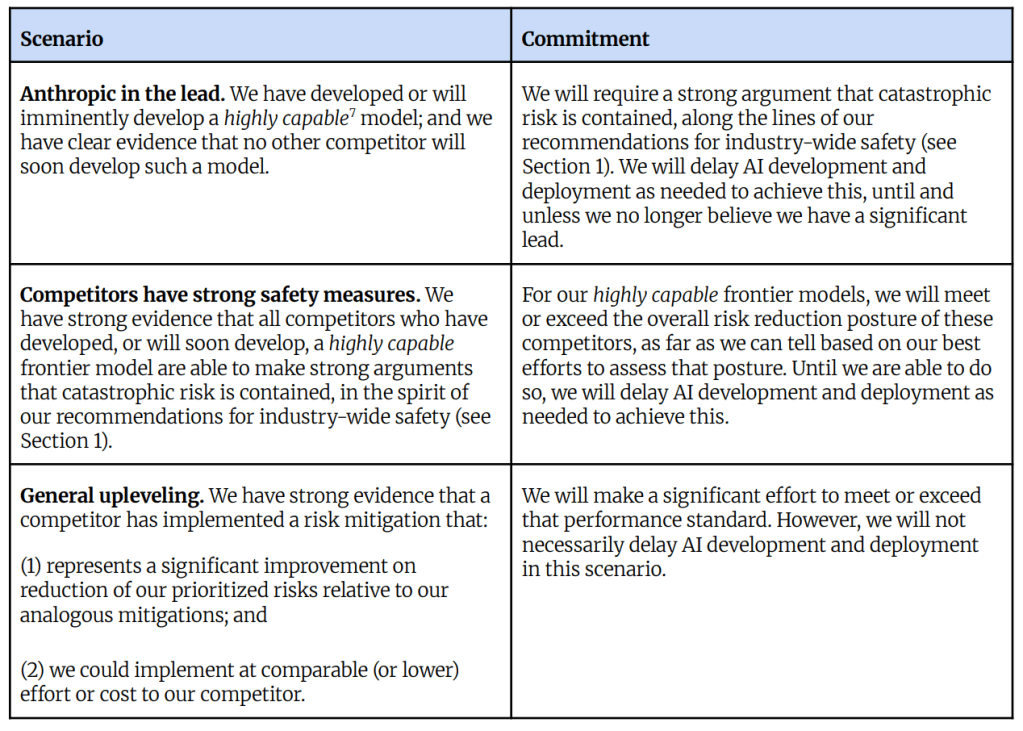
Last week over 40,000 signatories (and growing) have signed a letter calling for a ban on superintelligent AI until there is broad scientific consensus on safety as well as public buy-in. The signatories include some of the world’s famous people — like Prince Harry and Meghan Markle — and AI godfathers Geoffrey Hinton and Yoshua Bengio, as well as conservative communicators Steve Bannon and Glenn Beck and leaders in tech and national security. They cite the goal of leading AI companies to create AI systems that will “significantly outperform all humans on essentially all cognitive tasks” within the next decade. I’ve not signed it, but I am a fan of safely building superintelligence.
The response from those close to the US administration, including White House Senior AI Advisor Sriram Krishnan and former Senior AI Policy Advisor Dean Ball, is puzzling. They, supported by other public figures like Tyler Cowen, claim that any policy proposal to ban the use of dangerous AI systems globally would lead to a form of unchecked global centralization of power threatening US sovereignty. This is particularly puzzling given that the letter does not call for the centralization of power, and given that the bread and butter approach to international agreements on WMDs (chemical, nuclear, and biological) is multilateral, not centralized. The UN has no army or nukes. Treaties to control the most dangerous technologies in the world are enforced by nation-states.
Multilateral agreements are the bread and butter of arms control
Take for example the Partial Nuclear Test Ban Treaty ratified under President Kennedy in 1963, prohibiting the detonation of nuclear weapons above ground in order to contain nuclear fallout and limit the proliferation of nuclear weapons. It started as an agreement between just three nuclear-armed nations: the Soviet Union, the United States, and the United Kingdom. Once the three countries with the most powerful technology had agreed not to do testing, other countries had no choice but to comply, and 123 other countries signed the treaty. This treaty and its more comprehensive follow-on treaty in ’96 haven’t been 100% fool-proof, but they reduced the number of nuclear tests by several orders of magnitude.
Immediately following on the Partial Nuclear Test Ban Treaty was the Nuclear Nonproliferation Treaty, widely seen as one of the most successful treaties of all time. The Nuclear Nonproliferation Treaty was negotiated by 18 countries and then spread to the rest of the world. Participating states agree not to build nuclear weapons in or transfer them to non-nuclear states, and to let a central authority check whether their use of nuclear energy is for peaceable purposes — building power plants, not bombs. While the NPT has a central monitoring authority (the International Atomic Energy Agency), its mandates are enforced by countries. The International Atomic Energy Agency has no army and no ability to enforce nations to stop building nuclear weapons. So if a non-nuclear state is nuclearizing, other countries need to pressure that country into stopping: through sanctions or, exceptionally, an invasion to procure nuclear materials. This is why the US entered Iran and Iraq to search for nuclearization efforts, not the IAEA. The incentive countries have not to nuclearize has nothing to do with a central coercive authority.
If we choose to, we can do the same thing with superintelligence. Much like in 1963 in the nuclear context, today there are only three countries who have advanced AI capabilities: the US, the UK, and China. If these three countries agree not to build superintelligence, they can enforce this agreement multilaterally: by checking to make sure that each country is abiding by the terms of the deal, and then enforcing it directly. If the three AI superpowers agree to the terms of the deal, then every other country will have no choice but to agree, and to participate in efforts to uphold the bargain.
Verification
It is of course very important that this treaty is fool-proof. Signing on a dotted line does not magically mean that countries will not build superintelligence. And if the US, UK, and China agree not to build superintelligence but China or the UK secretly defects, and somehow succeeds in secret, then that is a threat to US sovereignty. Moreover, if any country believes that other countries may secretly defect, then they have no incentive to participate. So multilateral agreements need rigorous verification to make sure that no one can credibly defect. I think what this looks like is a system of sharing key model capability data and safety properties with agreeing nations to rigorously demonstrate that no one is violating the terms of the treaty. If this is in question, the treaty is enforced the normal way that arms treaties are enforced, with bilateral sanctions and coercion.
Fortunately in the case of AI there are numerous options for verification. In the context of nuclear weapons, verification comes in the form of facility audits by the IAEA. And as part of a multilateral agreement on superintelligence, we could agree to this kind of multilateral auditing, whether centralized or through a series of bilateral audits. While algorithmic secrets have proliferated faster than Labubu dolls, it would be ideal to set these audits up in a way that did not lead to leaking secrets to geopolitical adversaries, such as by allowing countries to test various high level safety and capabilities features of each others’ models and data centers, but without getting access to the weights.
If this fails, I’m confident that the US and Chinese national intelligence agencies will manage to fill the gaps with espionage. If intelligence agencies can penetrate air-gapped nuclear facilities, they’ll have no problem acquiring data about model capabilities without physically going to all of the data centers, and with finding new data centers via satellite imagery without having to be told where they are.
But if we want stronger forms of verification, there are software and hardware solutions. Everything AI can do is a complicated algorithm. These algorithms can increasingly be audited autonomously to find out what the model is capable of and prove things about the training run. So AGI projects could install secure, but open and auditable software in their data centers that checks for key properties and shares that information with heads of states that are parties to the agreement, collecting and reporting only the minimum necessary information to verify that no country is building superintelligence.
Implications
Probably no one will build superintelligence in the next decade. AI progress has consistently surprised experts, and in human history we have twice seen new technologies emerge that created a 10-100x rate change economic growth, during the agricultural and industrial revolution. But this is a historically rare occurrence and not something we should take for granted. So we need to build robust policies that prepare us for possible imminent superintelligence but don’t go all-in on something ultimately unlikely.
I think that this means taking no-regret options that pave the way for enforceable multilateral agreements on superintelligence while avoiding an increase in concentration, nonproliferation, or bureaucratic red-tape. This means building out the technical foundations for international audits, having Track 1 dialogues to create shared political understanding, giving governments visibility into frontier AI systems, their capabilities, and their foibles to know whether we are approaching a cliff, and building out increasingly clear Frontier Safety Policies at top labs so we can at least define superintelligence, draw red lines for actually scary capabilities, and determine what scientific consensus in the safety of superintelligence would actually amount to. This also means we need some 80-page papers on political economy, like Tyler Cowen suggests, so we can proactively think about what is going to happen in economic equilibrium under such a treaty. But if we’re going to build out the technical infrastructure and the knowledge base, it would be helpful if the White House didn’t decry any attempt to build out this optionality as a covert attempted power grab, and instead encouraged building out this neutral set of knowledge and technology that the White House can then choose deploy if AI scares us all in a few years.
And whether or not we choose to ban superintelligence, the bottom line is that it’s clearly not the case that the only way to internationally regulate dangerous AI development and applications is with a coercive central authority. I can forgive people for thinking it is, given Nick Bostrom’s scary essays on the possible need for international surveillance, and David Sacks’s admittedly surprising rejection of compute governance, a very centralizing approach that would ensure that America maintains international control over all of the chips it produces, leading to probably too much American sovereignty. But centralization is not the only or the best way forward. And if we want a polycentric system of governance going forward, I think the way to do that is with enforceable multilateral agreements on what red lines are too far rather than an anything-goes race towards the absolute concentration of corporate power through superintelligence.