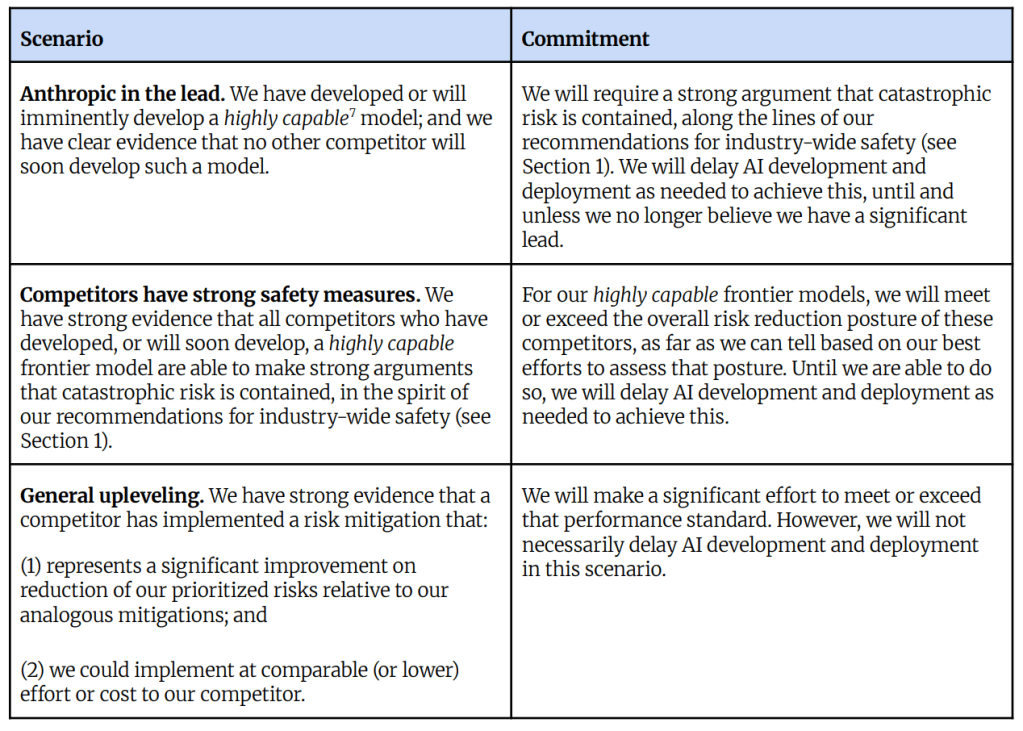
Or: How to verify verificationism
Before the second world war ripped the continent apart, continental Europe had its scientific golden age. Over the course of a few short decades it nurtured Einstein, Von Neumann, the earliest formulations of classical economics, advances in logic that would form the basis for linguistics and computing, and logical positivism. At the core of this explosion in ideas was a full-throated commitment to empiricism — or more specifically, an attempt to write ideas as clearly and rigorously as possible so that we can specify precisely what they predict and see how well they succeed in their predictions. In Vienna coffee houses, scientists and philosophers gathered to try to rebuild the foundations of science after the earthshattering discovery of general relativity, to debate the scientific usefulness of the atom, and to bemoan the success of their rivals Heidegger and Freud, whose ideas they deemed too unclear to critique.
At the center of this philosophical revolution were the logical positivists: Otto Neurath the giant, Rudolph Carnap the systematizer, Ludwig Wittgenstein the perfectionist, and Bertrand Russell, the pacifist. The positivists were so deeply committed to empirical discovery and transparent inquiry that they tried to put these very ideas themselves on a firm scientific foundation. They called the resulting principle “the verificationist criterion of meaning”, or “verificationism” for short. Verificationism is the view that the very meaning of a sentence is how you would go about proving it empirically. So the sentence “Bob owns a car” means something like “if you check state records you’ll find a registration for a car in Bob’s name.” And the sentence “there are an even number of rocks on Mars” means “if you go to Mars and you count all of the rocks using our number system, you’ll find that the number is a multiple of two.”
It doesn’t sound like a very revolutionary principle, but it actually rules out most areas of philosophy just based on how language works. What scientific process of discovery would you use to figure out whether eating meat is morally permissible? What process would you use to figure out if God exists? Or to determine whether a ship is really the Ship of Theseus after you’ve replaced all of its parts?
To the positivists, these questions were simply nonsense. According to their philosophy of language, claims like “meat is murder” or “God exists” or “the new ship is really the Ship of Theseus” don’t mean anything at all. They’re more vacuous than the outer reaches of space. We could, of course, redefine these sentences to be empirically verifiable — for example if by “God” we mean “love”, then we can just check if love exists, or if for the Ship of Theseus we’re just using our ordinary naming conventions as a society, then we can just check if our normal naming conventions call this bundle of sticks “Theseus.” But the traditional preoccupations of armchair philosophy, reflecting on what really exists beyond science and beyond our conventions, is a mere psuedoproblem: pushing words around on a page but not actually saying anything. The only claims that verificationists took seriously were empirical claims that you could prove with science, and logical claims like tautologies (A = A). With the verificationist principle in hand, you could summarily dismiss nearly all of philosophical thought as trivial and move on to real problems. “What we cannot speak of, we must pass over in silence.”
This idea that most of our philosophical practice might be completely empty is not as crazy as it might sound. There are lots of sentences that seem well formed in English but actually don’t mean anything at all. Take the famous “colorless green ideas sleep furiously.” Say it out loud to your roommate and they will probably try to think through it and understand what you just said. But it doesn’t mean anything, it’s just contradictions slapped together. Or take the notion of “God.” There are a number of philosophers who think that the very idea of God contains a logical contradiction. For example, some philosophers have argued that you couldn’t have a morally perfect, all powerful creator, because such a being could always improve the world by making more happy people or more beautiful flowers. And if you’re morally perfect, it’s in the very concept that you can’t do worse than you might have otherwise done.1 So a classical, three omni God is literally incoherent. I think we should take this argument seriously (I actually think it’s convincing!), and if so then we have to take seriously the idea that deeply held ideas and concepts that seem as clear as day to us might actually be fundamentally incoherent. Finally, take Kant, whose philosophy of space implied that it was simply incoherent to think of space as having a shape — the human mind cannot comprehend it! Given the discoveries of Einstein, that is not as tautologous as he thought!
Verificationism was a vibrant tradition that captured the interest of many of the brightest minds in Europe. But it died a death of attrition and genocide. The threads of verificationism gradually unraveled as its founders attempted to make sense of counterfactuals and probabilities, core ideas like analyticity and reductionism, and the foundations of mathematics and set theory. These were not obviously decisive problems, and the founders might have been able to solve them, but it turned out it was hard to be a Jewish scientist in Vienna decrying Nazi race science as unverifiable pseudoscience. A couple positivists were murdered by the Nazis, others fled to the US and Britain. Soon, the program splintered apart into a number of distinct research programs on scientific confirmation.
Today you will only ever come across logical positivism as an example of a failed idea, relegated to the dustbin of history because it didn’t work. Philosophers universally dismiss it, which I personally find very strange given the bizarre ideas that philosophers continue to debate in the academy, like whether you really know there is an external world or you are secretly just a brain in a vat, or whether language is impossible without the existence of an infinitely large multiverse. I think, at worst, verificationism faces some thorny obstacles and is in need of a research program to see if it can work. (What philosophical worldview isn’t??)
Two Key Objections to Positivism
Philosophers today take the following two objections to decisively put logical positivism to rest:
- Clearly there are facts that are not empirical. For example, there are ethical facts (meat is murder), facts about universals (what is the Ship of Theseus really?) and facts about mathematics (which can’t be empirical, right?).
and
- Verificationism is self-refuting! Verificationists say that there are only truths of science, but that is not a scientific statement!
I admit that these are very good objections. But they are not the kinds of objections that philosophers usually regard as decisive — enough to relegate a theory to the dustbin of history, rather than to see it as a very interesting claim in need of rehabilitation and defense. I think verificationism can still be salvaged.
Let’s consider the first objection first. I don’t think it’s clear at all that there are facts that are not empirical. According to the 2020 PhilPapers survey (a survey of all philosophers in the discipline):
- Only 62% of philosophers accept moral realism,
- 50% of philosophers are methodological naturalists,
- 52% of philosophers think consciousness is physical,
- And 44% of philosophers think that we can only learn things through empirical discovery!
While people can mean different things by these terms, that really doesn’t sound like a discipline that has collectively decided that there are obviously facts that aren’t empirical. On one way of interpreting the data, nearly half of philosophers think that there might be just particles, void, and our attempts to make sense of it all.
Over the last 400 years empiricists have shown a lot of resilience to criticism, coming up with a variety of positions that attempt to make sense of our philosophical practice without invoking any mysterious entities or gods of the gaps. Moral antirealists think that we can make sense of our moral discourse just by treating it as psychology: we deeply care about and are motivated by certain values, and it’s therefore totally sensible for us to commit our lives to them. Ontological antirealists have argued that when we’re debating whether a ship is really the Ship of Theseus, we’re really just negotiating how we should use the phrase “Ship of Theseus”, and there are better and worse ways to use this phrase depending on the purpose we’re using it for. There’s even theistic antirealists like the late bishop John Shelby Spong, who argued that when we’re talking about God we’re really trying to capture something deeply meaningful about our own aesthetic and ethical experience.
Meanwhile, defenders of moral realism, ontological realism, and theistic realism haven’t exactly given us a clear picture of how knowledge of these facts is supposed to work. How did we just happen to figure out the moral truth that is written in the stars? Philosophers have tried to give answers to this question but it remains pretty mysterious.
I’ll admit that mathematical knowledge is a tricky one. Math can’t just be a fact about our desires or conventions because it works — planes fly and engines combust. And while we can perhaps redescribe some of this math as just facts about physics, we can also prove lots of interesting theorems about, say, prime numbers that seem really true and fit together in our system of math even though they aren’t referring to anything in the world. We can’t explain mathematical practice without, well, math, and there is nothing we can empirically observe that is math.
But I see the project of putting math on a firm empirical foundation as a very interesting research program that should be pursued rather than something that is so hopeless that we are forced to go back to Plato’s Forms. There is an esteemed tradition of trying to put mathematics in good scientific standing, going back to John Stuart Mill, who argued that arithmetic is a truth about our local physics (if we were in a universe where every time we added one thing to another thing then suddenly there were three things, then 1 + 1 would be 3!) and before that Immanuel Kant, who attempted to ground geometry in the way that our brain shapes our understanding of the world around us (we can’t know if geometry is really true, we just know that brains like ours are forced to believe in it). Today these traditions are carried out in logicist, constructivist, and formalist research programs. (Which, according to PhilPapers, are certainly not dismissed!)
And once again, it’s not like mathematical realists have offered a better account of how we come to know mathematical facts! They’re written in the stars and then… what happens? How do these facts enter our mathematical practice if they’re not facts about our physical world but about some non-physical thing? We know that there’s no largest prime number through our mystical access to the Forms?
So I don’t think it’s at all clear that we need to accept a priori knowledge of the world from our armchairs, and that some things we can’t just figure out empirically. These are really tricky challenges, of course, but there’s certainly no answer we can just take for granted here.
What about the second objection, that positivism is self-refuting? Well, I first want to point out that we take seriously various ideas that have been claimed to be self-refuting. For example, it turns out that it’s pretty hard to come up with an epistemology that doesn’t refute or undermine itself in some way. In peer disagreement, the view that we should take other views as seriously as our own is seen as self-undermining, because if your peer rejects this view then you should too. But this view is still widely defended. And Alvin Plantinga has argued that naturalism is self-defeating, because if your brain evolved through random selection how can you trust it to tell you the truth about philosophical questions? But that hasn’t made all of the atheists throw themselves at the altar and come to Jesus. (Or, say, become skeptical Kantians, which is the stance that I adopt.) Platonism says that metaphysical truths are written in the stars and don’t causally interact with us. How do we then have knowledge of that?
It turns out epistemology is hard! It’s hard to come up with a position that is well-grounded because, as Merleau-Ponty argued, we can’t step outside of our own knowledge and examine its edges and its foundation. We can only use our existing concepts and frameworks to evaluate themselves, rather than to find some neutral perspective from which to critique them.
But don’t worry, I’m not going to leave you with “epistemology is hard, so if we gotta pick something we might as well go with verificationism.” I actually think that there are two excellent direct responses to the self-undermining objection to verificationism. These are sometimes called “left” and “right” positivism.
Two Formulations of Positivism that Survive Self-refutation
“Left” positivism is an expressivist position.2 That is, it’s not claiming that positivism is true with a capital T. It’s just saying: “hey guys, I really don’t think this whole philosophy thing is working out. We’ve spent thousands of years trying to make sense of the sound of one hand clapping and we are no closer to making any progress. By contrast look at science, which has given us medicine and transportation and nuclear fission! How about we focus on stuff that we can verify because that’s at least a tractable area where we can make progress and form agreement.” The left positivist furthermore says “I was never trying to put forward verificationism as a True Principle, I was just recommending that you adopt it, because things seem to go much better when we take this approach.”3 So the left positivist gets out of the self-refuting objection by denying that they were trying to make a truth-claim in the first place.
Then there’s right positivism, which I think is the more interesting position. Right positivism bites down on the bullet hard, saying that verificationism is actually a scientific truth. After all, what is verificationism if not an empirical claim about how language — or even the human mind — works? If verificationism is a claim about science then it can be verified after all: it’s self-endorsing.
Here the verificationist can take inspiration from the original Ur-empiricist David Hume.4 Hume’s philosophy of mind said that the kind of animal we are gets all of its information from observing the environment. We start out as an infant not knowing much of anything at all, and then we use our five senses to gather information about the world and form new ideas. Given that all of the information we have comes from our senses, then, all of our thoughts and ideas must be based on our senses. Where would other ideas even come from? God?
If all of the ingredients for our thoughts come from the five senses, then the only stuff we can even think about is some kind of construction we’ve made out of our sensory experiences. We can think of a screaming purple banana because we’ve taken in both bananas and the color purple with our eyes and we’ve taken in the sound of a scream with our ears, and we combine these together to create a new idea. We can think of the concept of horses-in-general because we’ve seen lots of horses and can imagine something that is the average of all of the horses we’ve seen, combining parts of other horses.
On the other hand, for an idea like God or objective morality, where would that even come from? All we’re doing is combining unrelated ideas. In the case of God, we’re smooshing together infinity, goodness, power, knowledge, and a personality. In the case of objective morality, we’re smooshing together our deeply held values and the notion of objectivity. But why think that we can combine terms in this way and they remain meaningful? Maybe this is just another case of colorless green ideas sleeping furiously.
In this sense, Hume thinks of humans as much like today’s large language models: we can construct new ideas, but only based on what is in our training data. (In this case, our experiences.) We can’t just generate something wholly new that is completely unrelated to anything in our data.
Hume’s philosophy of mind is probably too empiricist. Modern developmental psychology implies that not everything we learn comes from our environment. We’re not a totally blank slate, and some basic structure we’re just born with. But does that basic structure imply that we can clearly and distinctly understand the idea of a metaphysical universal any more than it implies that we can understand the idea of a perfectly spherical cube?
Fortunately we don’t have to simply speculate. Right positivism says that if this is true it is a truth of science, which we can empirically investigate and decisively demonstrate. To determine its truth status, cognitive scientists could explore the nature of our concepts and see whether it is possible for us to form ideas like the idea of God or if they’re only as well-formed in our minds as the perfectly spherical cube — ideas that have the right semantic structure but don’t actually fit together at all.
If we found out that the ideas of God and objective morality (for example) were represented in the same hollow way as “colorless green ideas sleep furiously,” then this would count as empirical vindication of the claim that these ideas are cognitively meaningless. If we further determined that the only ideas that were cognitively meaningful were empirical ideas and logical facts, then this would count as empirical vindication of positivism. Verificationism verified.
I have no idea if this could actually work, and the specific version of verificationism vindicated might have to be constructed in a somewhat post hoc way, depending on what we find empirically. (That’s how science normally advances!) But it seems like an interesting project worthy of investigation, and shows that the verificationist criterion of meaning (at least on certain interpretations) is not self-undermining. I think we should be curious about this, and explore what this means, rather than continue to repeat the false but convenient cautionary tale of a self-refuting theory.
This research program could be surprisingly important. Not only would it tell us about the nature of our selves and resolve almost all philosophical disputes, but it might be the only way forward through intractable philosophical debates. The biggest philosophical debate since Plato is rationalism vs empiricism. The rationalists say that we can discover truths simply by reflecting without any empirical observations, and the empiricists say that we cannot. Because rationalists all accept the results of science (how could they dispute them?) if positivism could be proven with science, the rationalists would have to give up on their paradigm and become empiricists.
What other way could this debate be resolved? Since we can’t empirically observe any of the things the rationalists talk about it would be impossible to come up with an empiricist argument for rationalism. So the only way you can argue for rationalism is on rationalist grounds, and as such there could be no convincing argument that makes a dogmatic empiricist become a rationalist. If you can’t convince an empiricist to become a rationalist, the only direction this could resolve would be by convincing a rationalist to become an empiricist, since they both accept the same body of empirical evidence. And how else could you convince a rationalist to become an empiricist on empirical grounds other than by using cognitive science to show them that their ideas are literally incoherent? This is why I think positivism might be the only way to make progress on this storied debate.
To be fair I am much more defeatist about this debate than many of my philosopher colleagues. Most of them seem to think that if we just keep talking to each other we’ll find an armchair argument that decisively proves empiricism or rationalism to everyone who hears it. I don’t see how this could work, but I’ve been wrong many times before.
Conclusions
Let’s sum up:
- The verificationist criterion of meaning says that there’s only logic and science, and we literally can’t meaningfully talk about anything else.
- This philosophy of language is universally rejected by philosophers on the grounds that it is too naturalistic and is self-refuting.
- But lots of philosophers are naturalists, naturalism has good resources to deal with objections, and the verificationist criterion is not self-refuting.
- In particular, there’s an expressivist version of verificationism that doesn’t attempt to make a truth-claim and a cognitivist version of verificationism that says it’s a discoverable truth in the cognitive sciences.
- I don’t know if the cognitive science program would work, but I think it’s worth a serious go, rather than deserving of derision.
- If it did work, it would resolve most open questions in philosophy and it might be the only path forward to reconcile different epistemological perspectives.
The main upshot of all of this is that verificationism isn’t obviously false and should be seen as a live position in philosophy — the biggest of big-if-true positions! Graduate students should work on it free of embarrassment and lecturers should stop teaching the view as a relic of history that we now know to be false. And there could be a lot of fruitful work to progress verificationism with all of the new tools we’ve developed in logic, language, and cognitive science over the century since its demise.5
It’s not at all clear to me that positivism will work. While most of the objections to positivism (e.g. about counterfactuals) are really insider critiques that the positivists were working on figuring out, and just require a bit of reformulation of the principle, others could be devastating (e.g. Quine’s rejection of analyticity). But this is just what a fruitful philosophical paradigm looks like. If you make your ideas precise enough you’re going to find problems, and the really interesting work lies in trying to solve them.